Introduction
Erudite will download articles from Instapaper or Pocket, convert them to an appropriate format such as EPUB or MOBI, and add them to your Calibre ebook library. It is a command-line driven tool.
This documentation is also available in EPUB and MOBI ebook formats.
Erudite is distributed under the Apache License 2.0.
How It Works
Erudite takes articles from a source (such as Instapaper or Pocket) and uses a HTML template file and a set of configuration properties to produce the appropriately formatted ebook files and (optionally) add them to your Calibre ebook library.
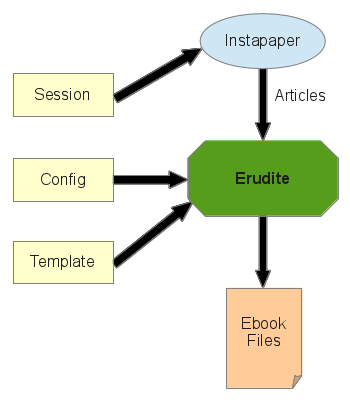
Session File
The session file holds the details necessary for accessing your Instapaper or Pocket session.
Configuration
The configuration file is a standard set of key/value properties that
tell Erudite how to process each article. Erudite first produces a HTML
version of the article in an easy to read format, then uses Calibre’s
ebook-convert
program to convert to the desired file type such as EPUB or MOBI. It can
then either save the file to a folder, or add it to a
Calibre ebook library.
Template
This is a HTML template used to produce the readable version of an article. This is optional as Erudite has an default HTML template it normally will use, but the option is available for advanced customisation.
Usage
Run the erudite.jar file with no arguments in order to see the full
usage.
java -jar erudite.jar
The full usage is shown here and may look a little intimidating, but we will break it down for each function later:
Erudite 2.2
Initialise a session, you must do this before you can process anything.
usage: init <source> [<file>]
<source>: Where you'll be pulling articles from.
One of "instapaper" or "pocket".
<file>: Where to save the session data.
Default is /home/user/.erudite/session.dat
Produce a fully commented configuration file.
usage: config [<file>]
<file>: Where to save the configuration file.
Default is /home/user/.erudite/session.properties
Produce a copy of the internally used template file.
usage: template [<file>]
<file>: Where to save the template file.
Default is /home/user/.erudite/session.html
Process articles from a session.
usage: process [-v | -q | -S] [-c <file>] [-s <file>]
-c <arg> Configuration file to use.
-q Quiet output (only on errors).
-s <arg> Session file to use.
-S Silent output.
-v Verbose output.
List articles to be processed from a session.
usage: list [-v | -q | -S] [-c <file>] [-s <file>]
-c <arg> Configuration file to use.
-s <arg> Session file to use.
-v Verbose output.
Test the title munging in the configuration file
usage: titletest [-c <file>] <title>
-c <arg> Configuration file to use.
Default session file: /home/user/.erudite/session.dat
Default configuration file: /home/user/.erudite/session.properties
Default template file (optional): /home/user/.erudite/session.html
Initialise a Session
Before being able to process articles, you will need to initialise your session with one of Instapaper or Pocket.
You can generate this by running:
java -jar erudite.jar init instapaper
or
java -jar erudite.jar init pocket
For an Instapaper session, you will be prompted for your email and password. Neither of these are stored in the session file, only the session cookies (just like a browser).
Pocket is a little more involved. Erudite will need your user ID and password, and will also directed to the web site to generate an API key and grant permission to Erudite to access your account. Neither the user ID or password are stored in the session file, only the session cookies (just like a browser).
Create your Configuration
Before being able to process articles, you will need to create a configuration file for your session.
You can generate a fully annotated configuration file by running:
java -jar erudite.jar config
This saves the file in the default location (run java -jar erudite.jar
and look at the last few lines to see where this is). Open this with your
preferred text editor, read through the documentation provided within and
edit to suit your needs.
Process Articles
To download articles and convert them, run:
java -jar erudite.jar process
Other Things You Can Do
From the command line, you can also:
List Articles To Be Processed
To list the articles waiting at the web service to be processed, run:
java -jar erudite.jar list
Create a HTML Template
If you need to use a custom HTML template, start with the one used by Erudite by running:
java -jar erudite.jar template
or
java -jar erudite.jar template mytemplate.html
The first one will save the file in the default location (run java -jar erudite.jar and look at the last few lines to see where this is). The
second one saves the file to the specified location. Edit the template to
suit your needs and refer to it from the configuration file if necessary.
Test Your Title Munging Fu
In the annotated configuration file you are introduced to title munging. Sometimes the titles for articles need a little bit of cleaning up before being used in the produced document. Title mungers use regular expressions to perform substitutions to make titles more readable or sortable.
e.g., Change “Coding Horror: New Programming Jargon” to “New Programming Jargon « Coding Horror” so it sorts by the name of the article, not the name of the site it was from.
Refer to the annotated configuration file to see how title munging works.
After editing the title munging in your configuration file, you can test it works as expected by running:
java -jar erudite titletest This is my test title
Wrap the title in quotes if necessary for your command line.
A note of default file locations.
By default, Erudite will store its data files in the folder ~/.erudite
for Linux, and %HOMEPATH%\erudite for Windows. The default session file
is called session.dat.
By default the configuration and template files have the same path and
name as the session file, but with a .properties and .html extension
respectively.
Annotated Configuration File
Below is a fully annotated sample configuration file.
######################################## # This is a sample configuration file for Erudite. # http://evanmclean.com/software/erudite/ ######################################## # Include Another Configuration File. # # This is useful to share common settings between several different # sessions. Good candidates for a common settings file are things # like title munging, number of worker threads, program paths, output # profiles and calibre library paths. # # If the variable has only a file name, no folder, then it will be # searched for in the current folder and then the user data folder # (e.g., ~/.erudite). #include = common.properties ######################################## # A Note On Special Characters. # # The configuration file uses the backslash to make it easier to # insert special characters in values. These generally follow the # conventions of Java. \n for a new line, \t for a tab. \u0020 for a # Unicode character. However because of this, to insert a single # backslash, you need to use two: \\ # # For file paths under Windows you can use forward slashes if you # prefer, so C:\\Users\\fred\\erudite and C:/Users/fred/erudite are # the same. ######################################## # Title Munging # # Sometimes the titles for articles need a little bit of cleaning up # before being used for the produced document. For example, many web # sites use titles along the lines of "Web site name: Article name". # Generally I prefer the article name to come first so it would be # nice to have erudite swap these around. Below are some examples. # # Title mungers follow a standard regular expression syntax of # /regex/substitute/ # The substitute can contain \\1 to \\9 to insert captured groups # from the expression. #title = /Coding Horror:\\s+(.+)/\\1 « Coding Horror/ #title = /High Scalability - High Scalability -\\s+(.+)/\\1 « High Scalability/ # Swap anything with the format "site name » article name" # to "article name « site name" #title = /(.*)\\s+»\\s+(.*)/\\2 « \\1/ ######################################## # Worker Threads # # Erudite can process several articles in parallel, making overall # processing time shorter. Generally setting the number of worker # threads to the number of CPU cores is a good place to start. I # wouldn't set it to more than twice the number of cores. By default # Erudite processes articles one at a time (one worker thread.) #worker.threads = 4 ######################################## # Image Handling # # Erudite downloads the images referenced in articles so they can be # included while processing. The following variables control how # images are handled. # By default, if there is an error downloading an image, the article # will not be processed and an error is displayed. Set this variable # to true to ignore the error and remove the image tag from the HTML # instead. #image.ignore.errors = true # Use the two variables below to remove images that are less then a # certain width and/or height. This is helpful to eliminate less # useful things like web bugs. #image.min.width = 5 #image.min.height = 5 # Convert all images to PNG. This can reduce the possibility of weird # images (such as animated gifs) from making a document unloadable by # your ereader device. By default Erudite just uses images 'as is'. #image.to.png = true # Cache Control. The image handler can cache images for reuse for # each processor (or if multiple articles use the same image). You # can limit either by the total number of images the cache will # retain, or the total number of megabytes of data. By default # Erudite will cache 100MB of images. # ONLY set one of these, not both. #image.cache.max.members = 100 #image.cache.max.mb = 100 ######################################## # Templates # # Erudite uses a HTML template to create the full HTML document from # the content of the article pulled from Instapaper or other source. # By default Erudite looks for a template in the same folder and with # the same file name as the session file, but with a ".html" # extension instead. If it does not find this, it uses an internally # stored template. # # If neither of these suit, you can specify the name of a template # file to be used by all processors here. (You can also specify this # for each processor for fine-grained control if you need it.) # # If the variable has only a file name, no folder, then it will be # searched for it in the current folder and then the user data folder # (e.g., ~/.erudite). # template = template.html ######################################## # Footnotes # # By default Erudite generates a list of the links that are in the # article. If you don't want this for some reason set the variable # below to false. (You can also specify this for each processor for # fine-grained control if you need it.) # footnotes = false ######################################## # Hnsearch # # If set to true, Erudite will use hnsearch.com to look up the URL of # the article and see if it has a discussion thread on Hacker News. # If so, it will include a link to the discussion thread in the # document. (You can also specify this for each processor for # fine-grained control if you need it.) # hnsearch = true ######################################## # Folder For Saved Documents # # For processors that save the processed article (instead of adding # them to Calibre's library) you can specify the folder here. (You # can also specify this for each processor for fine-grained control # if you need it.) saveto = /home/fred/my-ebooks ######################################## # ebook-convert # # ebook-convert is one of the command-line tools provided by the # Calibre ebook management software. It is used by Erudite for # converting articles from HTML to EPUB, MOBI or any other format # ebook-convert will handle. # # The following variables relate to Erudite's use of ebook-convert. # Erudite will search the operating system's PATH environment # variable as well a few other typical locations for the location of # the ebook-convert executable. However if it cannot find it, you can # specify the full path for it here. #ebookconvert.prog = C:/Program Files/Caibre 2/ebook-convert.exe #ebookconvert.prog = /opt/calibre/ebook-convert # The output profile you want to use with ebook-convert depends on # your target ereader device. See here for possible values: # http://manual.calibre-ebook.com/cli/ebook-convert.html#cmdoption-ebook-convert--output-profile # # By default Erudite will not specify any output profile to # ebook-convert. (You can also specify one for each processor for # fine-grained control if you need it.) #ebookconvert.outputprofile = generic_eink ######################################## # calibredb # # calibredb is one of the command-line tools provided by the Calibre # ebook management software. It is used by Erudite to add the # processed document to your ebook library. # # The following variables relate to Erudite's use of calibredb # Erudite will search the operating system's PATH environment # variable as well a few other typical locations for the location of # the calibredb executable. However if it cannot find it, you can # specify the full path for it here. #calibredb.prog = C:/Program Files/Calibre 2/calibredb.exe #calibredb.prog = /opt/calibre/calibredb # By default, the calibre add command uses the library stored in # Calibre's settings. You can explicitly specify the library folder # you want to use here. (You can also specify this for each processor # for fine-grained control if you need it.) # See here for more details: #http://manual.calibre-ebook.com/cli/calibredb.html#cmdoption--library-path #calbiredb.library = /home/fred/my-ebook-library ######################################## # Instapaper Settings # The folder on Instapaper to read articles from. If not set, the # Read Later (default) folder is read. #folder = ToDownload # Once Erudite has successfully processed an article, you can decide # what you will do with the article on Instapaper. You have one of # four options: # # * Do nothing (the default). # * Archive it. # * Remove it (delete). # * Move it to another folder. # # Typically you should do something or Erudite will just process it again # the next time it runs. #on.complete = none #on.complete = archive #on.complete = remove #on.complete = move:Downloaded # You can also decide what to do with an article on Instapaper if # Erudite experiences an error while processing it. You have all the # same options as for on.complete but moving it to another folder is # probably what you want to do. #on.error = move:Erudite Error ######################################## # Pocket Settings # By default, Erudite will process all articles in Pocket that have not # been archived. You can filter this based on the presence or absence of a # tag, or if an article is flagged as a favourite or not. Usually you # will use this in combination with an on.complete and on.error action # (see below) to avoid processing the same articles again on subsequent # runs. # To only process articles flagged as a favourite: #filter = favourite # Or, to process articles that are not flagged as a favourite: #filter = !favourite # To only process articles with the tag "To Erudite": #filter = To Erudite # To process all articles that do not have the tag "No Erudite" #filter = !No Erudite # It is possible to combine favourite state and tags: #filter = favourite, !Erudite Error #filter = To Erudite, !Erudite Error #filter = !Erudite Processed, !Erudite Error # Once Erudite has successfully processed an article, you can decide what # you will do with the article on Pocket. You have one of # five options: # # * Do nothing (the default). # * Archive it. # * Remove it (delete). # * Favourite or un-favourite it. # * Add or remove a tag. # # Typically you should do something or Erudite will just process it again # the next time it runs. #on.complete = none #on.complete = archive #on.complete = remove #on.complete = favourite #on.complete = unfavourite #on.complete = tag:Erudite Processed #on.complete = untag:To Erudite # You can also decide what to do with an article on Pocket if Erudite # experiences an error while processing it. You have all the same options # as for on.complete but tagging it to indicate an error is probably what # you want to do. #on.error = tag:Erudite Error ######################################## ######################################## # Processors # # The bread and butter of Erudite. Each article is ran through one or # more processors. You can use processors to: # # * Save the article as a HTML file. # * Add the article to your Calibre ebook library as a HTML file. # * Convert the article to an ebook format such as EPUB or MOBI # and either save it or add it to your Calibre ebook library. # # Processors are declared as a comma separated list of identifiers. # The identifier then becomes the prefix of the variables used to # configure the processor. That way, you can have a bunch of # processors configured, and just pick which one you want to use with # one line. Example processor configurations are below. # This is the list of processors to run for each article. #processors = epub, savehmtl ######################################## # Common processor configuration variables # Type: The type of processor. One of: # # save # Saves the HTML to a file. Images are stored in a matching # "_files" suffixed folder. # # calibre # Save the HTML file directly to your Calibre ebook library. # # ebookconvert (or ebook-convert) # Convert the article from HTML to an ebook format such as # EPUB or MOBI. #procid.type = save #procid.type = calibre #procid.type = ebookconvert # Footnotes (optional): By default Erudite generates a list of the # links that are in the article. You can set this for all processors # with the "footnotes" variable declared above, and/or on an # individual basis as shown below. #procid.footnotes = false #procid.footnotes = true # Hnsearch (optional): If set to true, Erudite will use hnsearch.com # to look up the URL of the article and see if it has a discussion # thread on Hacker News. If so, it will include a link to the # discussion thread in the document. You can set this for all # processors with the "hnsearch" variable declared above, and/or on # an individual basis as shown below. #procid.hnsearch = true #procid.hnsearch = false # Template (optional): See the explanation for the "template" # variable above. You can set a specific template to be used just # for this processor instead of the default. #procid.template = template.html ######################################## # Saving a HTML File # # This type of processor will save the article as a HTML file in a # nominated folder. The name of the file will be based on the title # of the article and be ensured to be unique (it wont overwrite # existing files). If there are any images, a folder with the same # base name as the file and the suffix "_files" will be used to store # them. #savehtml.type = save # The folder to save the HTML files to. If this is not set then the # processor will use the value of the "saveto" common variable # described above. If neither is defined then an error will occur. #savehtml.saveto = /home/fred/my-ebooks # Optional, common processor variables described above. #savehtml.footnotes = true #savehtml.hnsearch = true #savehtml.template = template.html ######################################## # Add HTML To Your Calibre Ebook Library # # This type of processor will add the article in HTML format to your # Calibre ebook library. #addhtml.type = calibre # (Optional) Explicitly set the library folder you want to use. See # the description of "calibredb.library" above for more details. #addhtml.library = /home/fred/my-ebook-library # (Optional) The name you want to use as the author for this article # in your library's meta-data. By default Calibre uses "Unknown". #addhtml.author = Someone On The Web # (Optional) Zero or more extra options to pass to the calibredb # command line tool, which is used to add the document to the ebook # library. You'll want familiarity with the calibredb add command to # use this: # http://manual.calibre-ebook.com/cli/calibredb.html#calibredb-add #addhtml.option = --duplicates #addhtml.option = --tags=viaErudite # Optional, common processor variables described above. #addhtml.footnotes = true #addhtml.hnsearch = true #addhtml.template = template.html ######################################## # Convert to an Ebook Format # # Convert the article from HTML to an ebook format such as EPUB or # MOBI. After conversion the document can either be saved to a folder # or added to your Calibre ebook library. # # Some familiarity with Calibre's ebook-convert tool would be handy # to use this with confidence: # http://manual.calibre-ebook.com/cli/ebook-convert.html #conv.type = ebookconvert # The target file format. This is the extension on the end of the # file name that would be produced. It can be any format that # ebook-convert handles as an output. # http://manual.calibre-ebook.com/cli/ebook-convert.html #conv.filetype = pdf # (Optional) The output profile to be used. This depends on your # target ereader device. See the description of # "ebookconvert.outputprofile" above for more details. #conv.outputprofile = generic_eink # (Optional) The name you want to use as the author for this article # in your document's meta-data. By default Calibre uses "Unknown". #conv.author = Someone On The Web # (Optional) When producing an EPUB file, this wrap hack allows # better wrapping of long URLs by injecting zero width spaces into # the document. This may not work for some ereader devices so try it # and see. #conv.wrap.hack = true # (Optional) Zero or more extra options to pass to the ebook-convert # command line tool, which is used to covert the HTML text of the # article to the desired format. You'll want familiarity with the # ebook-convert command to use this: # http://manual.calibre-ebook.com/cli/ebook-convert.html #conv.option = --asciiize #conv.option = --change-justification=left # Optional, common processor variables described above. #conv.footnotes = true #conv.hnsearch = true #conv.template = template.html # What to do with the document once it has been converted? You can # either save it to a folder or add it to your Calibre ebook library. #conv.then = save #conv.then = calibre # When saving, you can specify the folder to save the document to. If # this is not set then the processor will use the value of the # "saveto" common variable described above. If neither is defined # then an error will occur. #conv.saveto = /home/fred/my-ebooks # For adding to your library you can use the following to pass # configuration settings to the calibredb add command: # # (Optional) Explicitly set the library folder you want to use. See # the description of "calibredb.library" above for more details. #conv.library = /home/fred/my-ebook-library # (Optional) Zero or more extra options to pass to the calibredb # command line tool, which is used to add the document to the ebook # library. You'll want familiarity with the calibredb add command to # use this: # http://manual.calibre-ebook.com/cli/calibredb.html#calibredb-add #conv.then.calibredb.option = --duplicates ######################################## # Example Conversions # # The following will convert a document to EPUB and add it to your # Calibre ebook library. epub.type = ebookconvert epub.filetype = epub epub.outputprofile = generic_eink epub.author = Someone on the Web epub.wrap.hack = true epub.option = --change-justification=left epub.option = --dont-split-on-page-breaks epub.option = --no-default-epub-cover epub.then = calibre # The following will convert a document to MOBI and save it to a # folder. mobi.type = ebookconvert mobi.filetype = mobi epub.outputprofile = kindle mobi.author = Someone on the Web mobi.option = --change-justification=left mobi.then = save mobi.saveto = /home/fred/my-ebooks
